
Both Solr and Elasticsearch include suggester components, which can be used to provide search engine users with suggested completions of queries as they type:
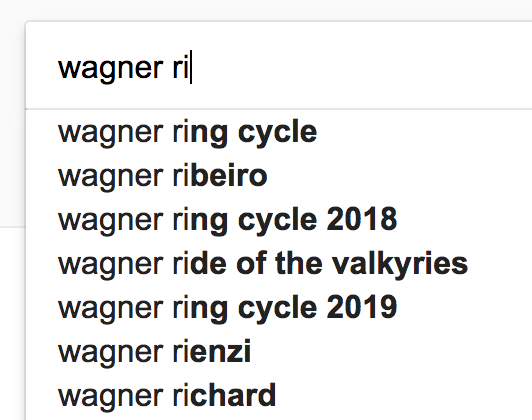 Query autocomplete has become an expected part of the search experience. Its benefits to the user include les...Continue reading
Query autocomplete has become an expected part of the search experience. Its benefits to the user include les...Continue reading
A search-based suggester for Elasticsearch with security filters
2




