
This is an edited transcript of a talk given by Alan Woodward of Flax and Martin Kleppmann at FOSDEM 2015. It was originally published on the Confluent blog.
Traditionally, search works like this: you have a large corpus of documents, and users write ad-hoc queries to find documents within that corpus. Documents may change from time to time, but on the whole, the corpus is fairly stable. However, with fast-changing data, it can be useful to turn this model on its head, and search over a stream of documents as they appear. For example, companies may want to detect whenever they are mentioned in a feed of news articles, or a Twitter user may want to see a continuous stream of tweets for a particular hashtag.
In this talk, we describe open source tools that enable search on streams: Luwak is a Lucene-based library for running many thousands of queries over a single document, with optimizations that make this process efficient. Samza is a stream processing framework based on Kafka, allowing real-time computations to be distributed across a cluster of machines. We show how Luwak and Samza can be combined into an efficient and scalable streaming search engine.

In this talk we’re going to discuss some work that we’ve been doing in the area of full-text search on streams. Perhaps you already know about normal search engines like Elasticsearch and Solr, but as we’ll see, searching on streams is quite a different problem, with some interesting challenges. Searching on streams becomes important when you’re dealing with real-time data that is rapidly changing. We’ll see some examples later of when you might need it.

But first of all, we should define what we mean with a stream. For our purposes, we’ll say that a stream is an append-only, totally ordered sequence of records (also called events or messages). For example, a log file is a stream: each record is a line of text with some structure, perhaps some metadata like a timestamp or severity, perhaps an exception stack trace. Every log record is appended to the end of the file.
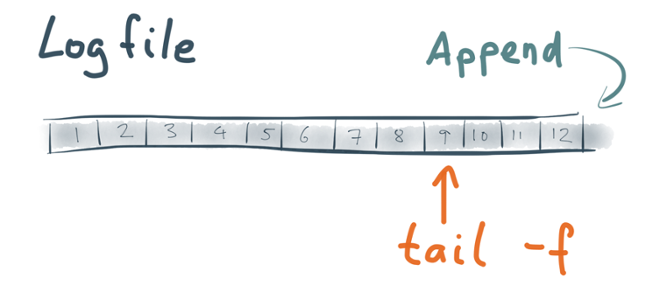
There are a few ways you can read the content of a stream. For example, you can start at the beginning of the file and read the entire file sequentially. Or you can use `tail -f` to watch the file for any new records that are appended, and be notified when new data appears. We call a process that writes to a stream a “producer”, and a process that reads from the stream a “consumer”.

Now say you’ve got some data in a stream, such as a log file, and you want to do full-text search on it. How do you go about doing that?
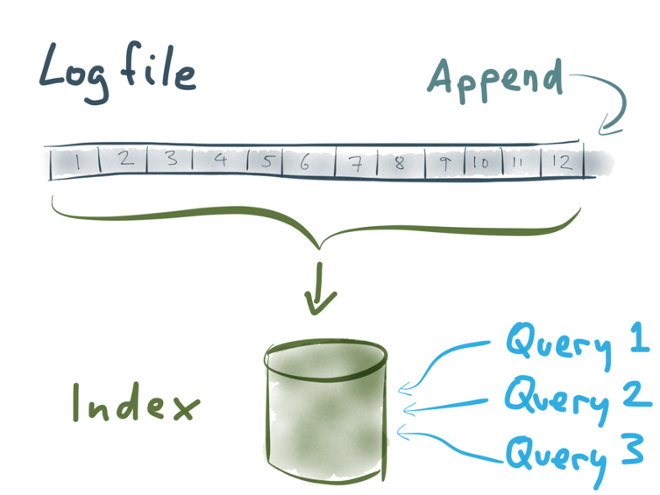
The traditional approach is to load everything into a big search index, perhaps something like Elasticsearch or Solr. ELK (Elasticsearch, Logstash and Kibana) is a currently trendy way of setting this up. That way you have the entire history of the stream searchable, and people can write any queries they want to search the index.
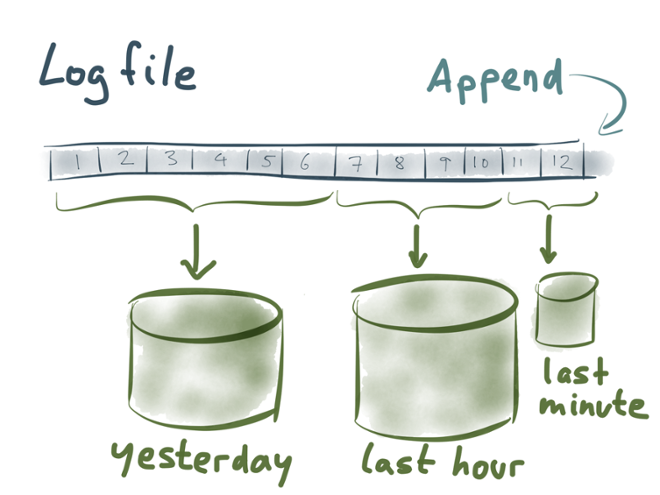
But what happens as new records are appended to the stream? You need to add them to an index in order to make them searchable. For example, you could imagine creating different indexes for different time periods: one for historical data, one for yesterday, one for the last hour, one for the last minute…
And this is basically what people mean when they talk about “near-real-time” search: create an index for documents that appeared very recently, and send any queries to that index as well as the older historical indexes.
Let’s talk about some examples of this kind of search in practice.
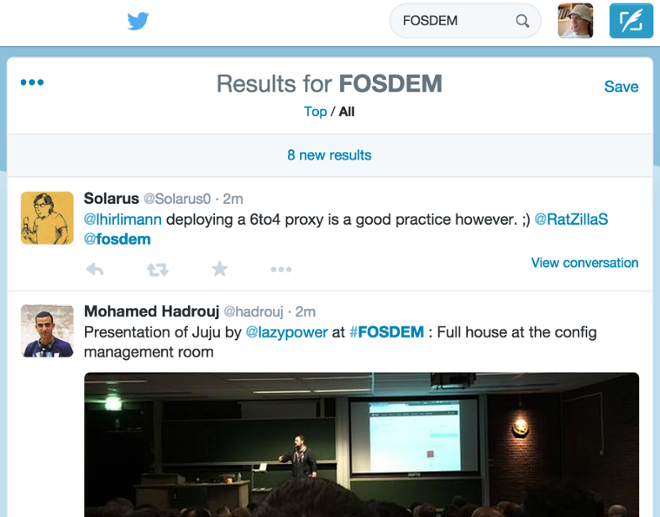
Take Twitter, for example. If you type something in the search box, you’ll see a list of tweets that match your search query, ranked by recency. The index includes all public tweets ever written, broken down by time period, similar to the diagram above.
But if you stay on that page for a while, notice that something happens: a bar appears at the top of the page, saying that there are new results for your query. What happened here? When you typed your search query, it seems that Twitter didn’t forget about the query the moment they returned the results to you. Rather, they must have remembered the query, and continued to search the stream of tweets for any new matches for your query. When new matches appear in the stream, they send a notification to your browser.
In this case, the stream we’re searching is Twitter’s so-called firehose of Tweets. I don’t know how they’ve implemented that. Perhaps they group tweets into batches — say, create an index for 10 seconds worth of tweets, and then run the queries from all open search sessions against that index. But somehow they are doing full-text search on a stream.
Another example is Google Alerts. This is a feature of Google where you can register some search queries with their system, and they send you an email notification when new web pages matching your query are published. For example, you might set up an alert for your name or company name, so that you find out when people write stuff about you.
Google internally has a stream of new web pages being discovered by its crawler, and Google Alerts allows you to register a query against that stream. Google remembers the query, and runs the query against every new document that is discovered and added to its index.
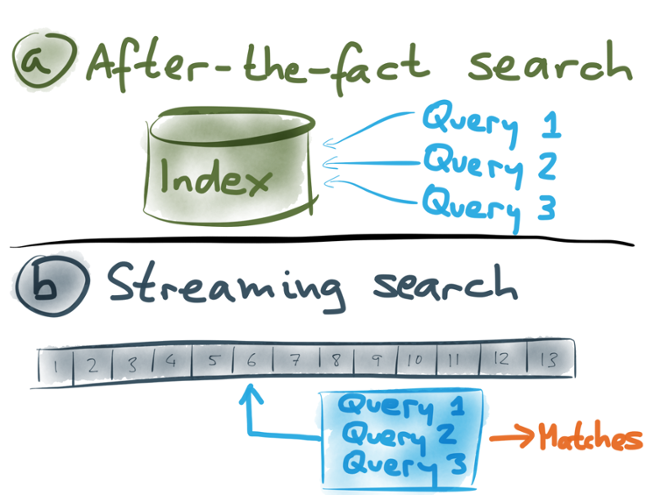
So it seems that we can divide search into two categories:
- In one case, you put all the documents in a big index, and people can search that index by writingad-hoc queries. We could call that after-the-fact search, because it’s searching a repositoryof historical documents that we received at some point in the past.
- In the other case, you register the queries in advance, and then the system checks each documentthat appears on a stream, to see whether it matches any of the registered queries. This is streaming search.
It often makes sense to combine these two: for example, in the Twitter case, both types of search are happening. You first get after-the-fact search results from the last 7 days, but while you have the search page open, your query is also registered for a stream search, so that you can follow the stream of tweets that match your query.
You might have seen this pattern in Elasticsearch Percolator, for example. The streaming search approach we’re describing here is similar to Percolator, but we think that it will scale better.
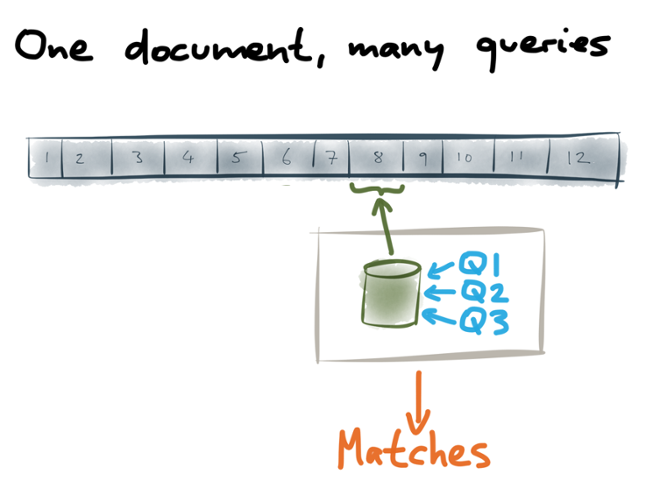
So, how do you actually implement streaming search? Well, we saw earlier that for near-real-time search, you construct a small index for recently added documents. We can take that approach to the extreme: for each new document that appears on a stream, we create a new index, containing just that one document. Then we can run through all of the registered queries, test each query against the one-document index, and output a list of all the queries that match the new document. A downstream system can then take those matches and notify the owners of the queries.

However, the question is: how efficient is this going to be when you have lots of queries, or very complex queries? If you only have a few hundred registered queries, you can pretty quickly run through all of those queries for every new document on the stream — but if you have hundreds of thousands of queries, it can get quite slow.
Also, if you have very complex queries, even just executing a single query can take a long time. I (Alan) work with some clients who provide media monitoring services (also known as clipping companies). They collect feeds of newspaper articles and other news from around the world, and their clients are companies who want to know whenever they are mentioned in the news. The media monitoring companies construct one big query for each client, and those queries can become really huge — a query might be hundreds of kilobytes long! They contain a large number of terms, have lots of nested boolean operators, and lots of exclusions (negated search terms).
To give just one example, in the UK there’s a magazine called “Which?“. If you simply search for the term “which”, you match a huge number of documents, since that’s such a common word in English. They have to construct really complex queries to filter out most of the noise.
So, if you have a large number of queries, or very complex queries, the streaming search becomes slow. We need to find ways of optimizing that. Observe this: the fastest query is a query that you never execute. So, if we can figure out which queries are definitely not going to match a given document, we can skip those queries entirely, and potentially save ourselves a lot of work.

Which brings us to Luwak, a library that Flax wrote in order to do efficient streaming search. Luwak is open source and builds upon Apache Lucene. It works the other way round from a normal search index: with a normal index, you first add documents to the index, and then you query it. Luwak turns this on its head: you first register queries with Luwak, and then match documents against them. Luwak tells you which of the registered queries match the document.
Let’s go a bit into the detail of how Luwak optimizes this matching process.
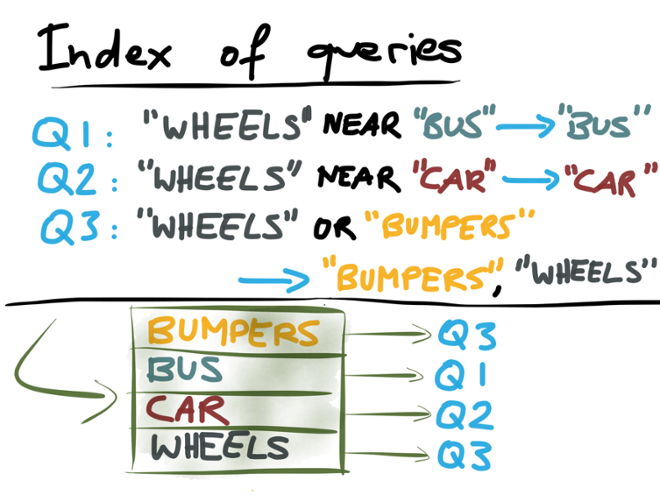
As I said, we want some way of figuring out which queries are definitely not going to match a document, so that we don’t need to bother executing those queries. In order to do this, we can do something unusual: we can index the queries! In search engines you normally index documents, but in this case we’re going to index the queries.
Let’s say we have three registered queries: Q1 is `”WHEELS” NEAR “BUS”`, Q2 is `”WHEELS” NEAR “CAR”`, and Q3 is `”WHEELS” OR “BUMPERS”`. First observe this: in a conjunction query (that is,a query like A AND B AND C), all the search terms must appear in the document for the query to match. (An operator like NEAR is a specialized form of AND that has an additional proximity restriction.) For example, a document must contain both “wheels” and “bus” in order to match Q1; if a document doesn’t contain the word “bus”, there’s no chance it can match Q1.
That means, we can arbitrarily pick one term from a conjunction and check whether the document contains that term. If the document doesn’t contain the term, we can be sure that the document won’t match the conjunction either.
On the other hand, a disjunction query (with an OR operator, like Q3 for example) matches if *any* of the search terms appear in the document. For example, if a document doesn’t contain “wheels”, it may nevertheless match Q3 if it contains “bumpers”. In this case, we must extract all of the terms from the disjunction; if any one of those terms appears in the document, we have to test the full query.
We can now take those terms that we extracted from queries (for example “bus” from Q1, “car” from Q2, and “bumpers” and “wheels” from Q3), and build an index of those terms. As I said, this is an index of queries, not of documents. The index is a dictionary from terms to queries: it maps terms to queries containing that term.
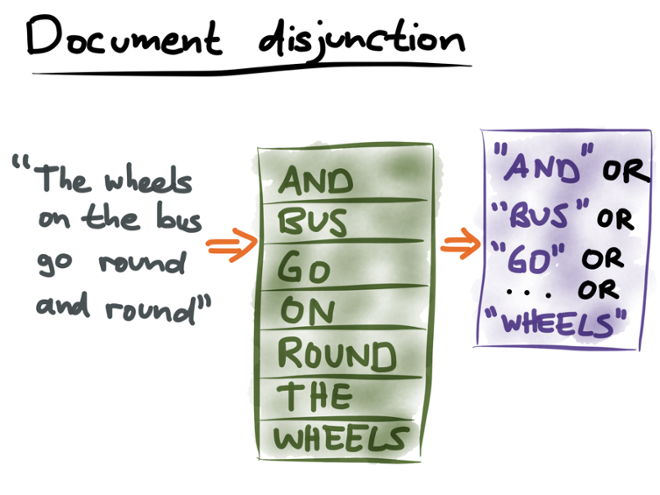
Now that we’ve taken all our registered queries and indexed them, we can move on to the next step: processing the stream of documents. For each document, we want to find all the queries that match. How do we go about doing this?
The trick is to take each document, and turn it into a query. (Previously we created an index of
queries. Now we’re turning a document into a query. How upside-down!) Namely, we take all the words (terms) that appear in the document, and construct a disjunction (OR) query from all of those words. Intuitively, this is saying: “find me all the queries that match any of the words in this document”. Creating an inverted index from a single document automatically gives us this list of terms.
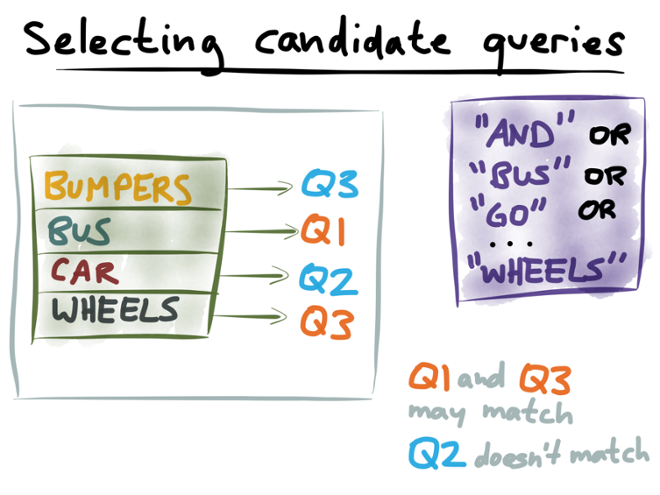
Now that we have created an index of queries, and turned a document into a query, we can figure out which queries match the document. First, we run the document disjunction query against the index of queries. This will tell us which queries may match the document.
In our example, we created the query index by extracting the term “bus” from Q1, the term “car” from Q2, and the terms “bumpers” and “wheels” from Q3. Also, we turned the document “The wheels on the bus go round and round” into the disjunction query:
"and" OR "bus" OR "go" OR "on" OR "round" OR "the" OR "wheels"
Running that disjunction query against the query index, we get a hit on the terms “bus” (Q1) and “wheels” (Q3), but the terms “bumpers” (Q3) and “car” (Q2) don’t appear in the document. Therefore we can conclude that Q1 and Q3 might match the document, but Q2 definitely doesn’t match the document.
The next step is then to run queries Q1 and Q3 against the document index, to see whether they really do match. But we don’t need to run Q2, because we’ve already established that it definitely doesn’t match.
This whole process of indexing queries may seem a bit complicated, but it is a really powerful optimization if you have a large number of queries. It can cut out 99% of the queries you would otherwise have to execute, and thus massively speed up searching on streams. As I said, the fastest query is one that you never even execute.
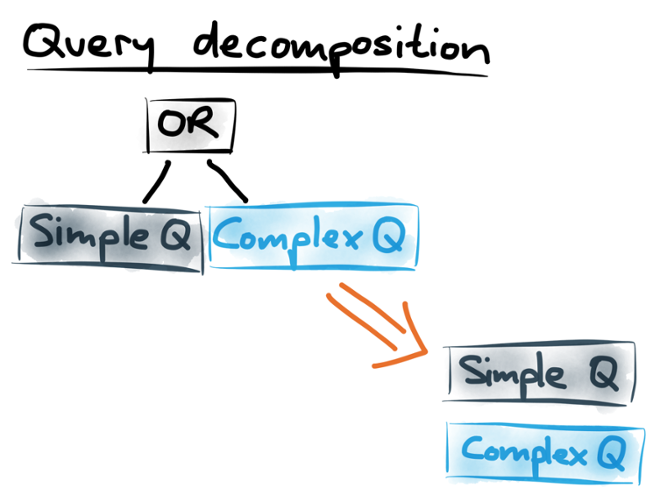
Besides indexing queries, there are other optimizations we can make. One particular optimization that we’ve found useful: if you have a big query that contains an OR operator at the top level, you can break that big query into smaller ones. That is especially useful if one of the subqueries is simple (fast to execute), and another one is complex (slow to execute).
Say we have a document that will match on the simple subquery, but not on the complex one. In the normal case, the whole query is run against the document, so we still pay the price for executing the complex subquery, even though it doesn’t match. If we decompose it into its constituent parts, however, then only the simple subquery will be selected, and we can avoid the performance hit of running the complex one.
We said earlier that when you’re indexing the queries, you can make some arbitrary choices about which terms to extract. For example, for the query “car” AND “bumpers”, you could choose either “car” or “bumpers” as the term to use in the query index. Which one should you choose?
It’s helpful to know how often each term occurs in your documents. For example, perhaps “car” is quite a common term, but “bumpers” is much more rare. In that case, it would be better to use “bumpers” in the query index, because it’s less likely to appear in documents. Only the small number of documents containing the term “bumpers” would then need to be matched against the query “car” AND “bumpers”, and you save yourself the effort of executing the query for the large number of documents that contain “car” but not “bumpers”.
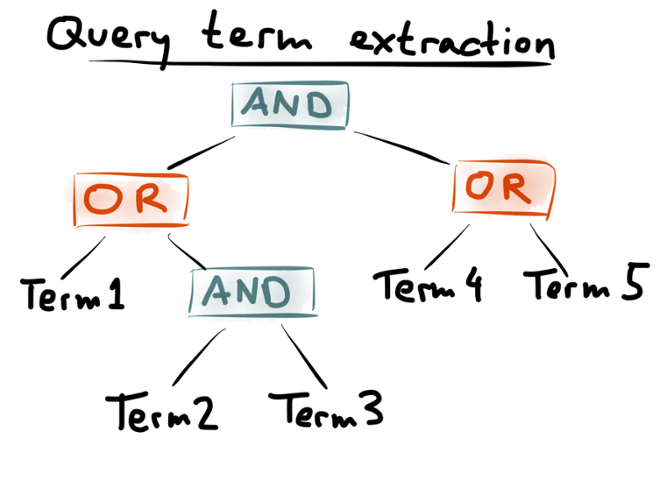
Another, more advanced optimization technique considers several different possibilities of extracting terms from queries. Take the query tree above, containing five terms and four boolean operators. Remember the rule for extracting terms that we established earlier: extract any one of the children of a conjunction (AND), but extract all of the children of a disjunction (OR). This means there are three different combinations of terms that you could extract from the above query tree:

Say you have a document “term1 term2 term3”: this document does not match the query (because neither of the required term4 or term5 appears). However, in the first two combinations above (term1 and term2 extracted, or term1 and term3 extracted), the document would nevertheless be selected to be matched against the query. In the third combination above (term4 and term5 extracted), the document wouldn’t be selected, because we can tell from the query index that it is definitely not going to match the query.
Can we make the query pre-selection more precise? Yes, we can! Rather than just extracting one (arbitrary) set of terms from the query, we can extract several sets of terms from the same uery, like the three above, and index them into separate fields (let’s call them _a, _b and _c). You hen run your document disjunction against all those fields, and the set of queries you need to un is the intersection of those results — a conjunction of disjunctions, if you like.
The document “term1 term2 term3”, which we previously turned into a simple disjunction of terms, now turns into something like this:
_a:(term1 OR term2 OR term3) AND _b:(term1 OR term2 OR term3) AND _c:(term1 OR term2 OR term3)
The first two terms of the conjunction match, but the third doesn’t, and so we don’t select this query. It’s still an approximation — you still need to execute the full query to be sure whether it matches or not — but with these optimizations you can further reduce the number of queries you need to execute.
Fortunately, Luwak has implemented all of these optimizations already, and they’re available for you to use today.
However, as described so far, Luwak runs on a single machine. At some point, you may have so many queries or such high throughput of documents that a single machine is not enough, even after you have applied all of these optimizations. Which brings us to the second half of this talk: scaling stream search across a cluster of machines.
At this point, Martin took over from Alan.

Rather than inventing our own distributed computing framework — which would be likely to go wrong, because distributed systems are hard — we’re going to build on a robust foundation. We’re going to use Apache Kafka and Apache Samza, two open source projects that originated at LinkedIn.
I’ll start by giving a bit of background about Kafka, and then talk about how we embedded Luwak inside Samza in order to scale out search on streams.
Kafka is a kind of message broker or message queue — that is, it takes messages that originate in one process (a producer), and delivers them to another process (a consumer). It does so in a scalable, fault-tolerant manner.
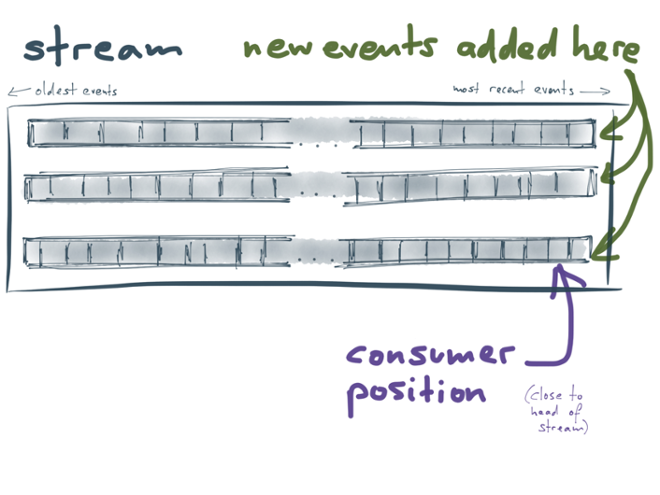
The way it works is simple but remarkably effective. You can imagine Kafka as one big, append-only file. Whenever a producer wants to send a new message to a stream, it simply appends it to the end of the file. That’s the only way how you can write to Kafka: by appending to the end of a file.
A consumer is like a `tail -f` on that file, just like what we described at the beginning of this talk. Each consumer reads the messages in the file sequentially, and each consumer has a current *position* or *offset* in this file. Thus, it knows that all messages before that position have already been read, and all messages after that position have not yet been read. This makes Kafka very efficient: the brokers don’t have to keep track of which consumer has seen which messages, because the consumers themselves just need to store their current position.
In order to scale across multiple machines, a Kafka stream is also *partitioned*. That means, there’s not just one append-only file, but several. Each partition is completely independent from the others, so different partitions can live on different machines.
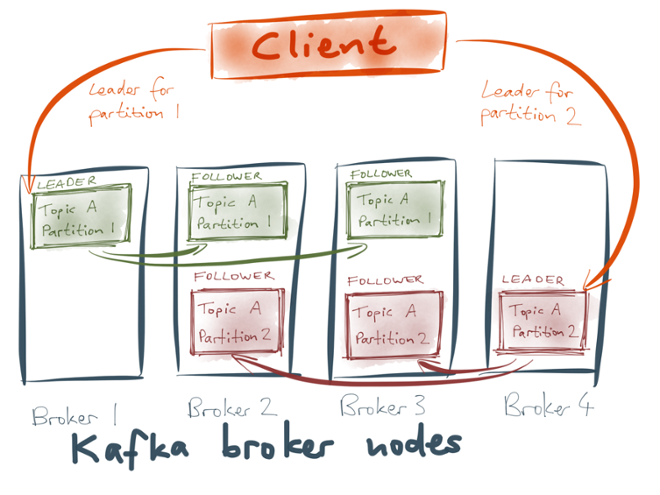
In addition, Kafka provides replication, i.e. maintaining a copy of the same data on multiple machines. This is important for fault tolerance — so that if one machine dies, you don’t lose any data, and everything keeps running.
Kafka does this using a leader/follower model. Each partition of a stream has a leader on one broker node, and a configurable number of followers on other broker nodes. All the new messages for a partition go to its leader, and Kafka replicates them from the leader to the followers. If a broker node goes down, and it was the leader for some partition, then one of the followers for that partition becomes the new leader.
Every message in Kafka has a key and a value (which can be arbitrary byte strings). The key is used for two different things: firstly, it determines which partition the message should go to (we make sure that all the messages with the same key go to the same partition, by choosing the partition based on a hash of the key). Secondly, it is used for *compaction*.
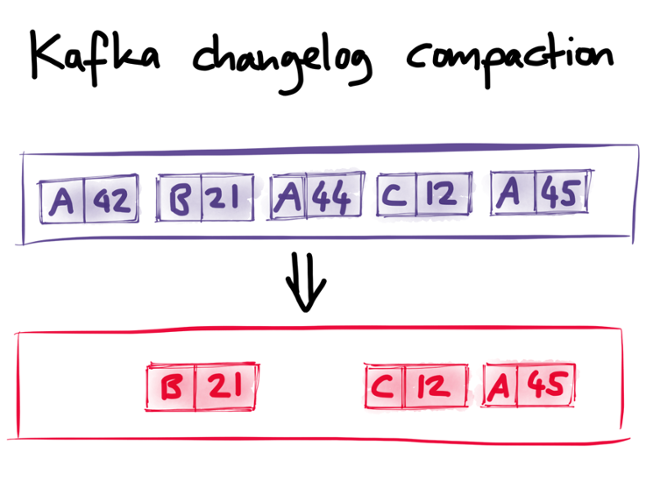
Compaction is an exception to Kafka’s otherwise strict append-only model. You don’t have to use compaction, but if you do turn it on, then Kafka keeps track of the keys in the stream. And if there are several messages with the same key, then Kafka is allowed to throw away older messages with that key — only the newest message for a given key is guaranteed to be retained.
In the picture above, there are originally three messages with key A, and compaction discards two of them. In effect, this means that later messages can “overwrite” earlier messages with the same key. This overwriting doesn’t happen immediately, but at some later time: compaction is done in a background thread, a bit like garbage collection.
A Kafka stream with compaction is thus similar to a database with a key-value data model. If a key is never overwritten, it is never discarded, so it stays in the stream forever. With compaction, we can thus keep a complete history of key-value pairs:
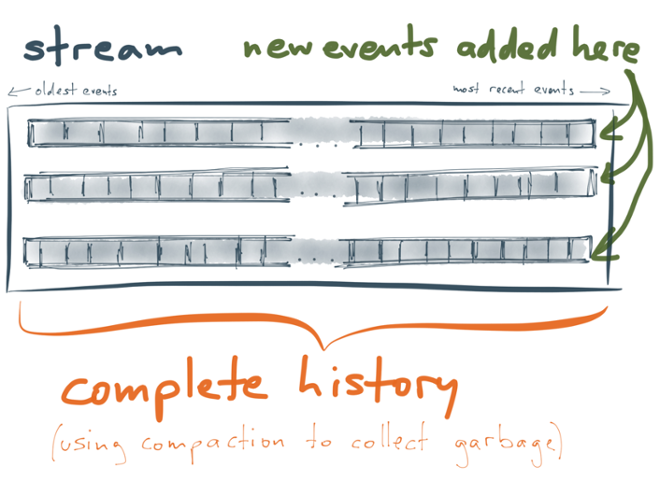
Without compaction, the stream would keep growing forever (the size of the stream is proportional to the number of messages ever sent). But with compaction, the size of the stream is proportional to the number of distinct keys — just like a database. If you can imagine storing all the keys and values in a database, you can equally well store all the keys and values in a Kafka stream.
Why is this useful? Well, if we want to use Luwak in a reliable manner, there is a problem we need to solve: when you register a query with Luwak, it is only kept in memory. Thus, whenever the Luwak process is restarted, it needs to reload its list of queries from stable storage into memory.
You could use a database for this, but using a Kafka stream has a big advantage: Luwak can consume the stream of queries, so it gets notified whenever someone registers a new query, modifies a registered query, or unregisters (deletes) a query. We simply use the query ID as the message key, and the query string as the message value (or a null value when a query is unregistered). And stream compaction ensures that the query stream doesn’t get too big.
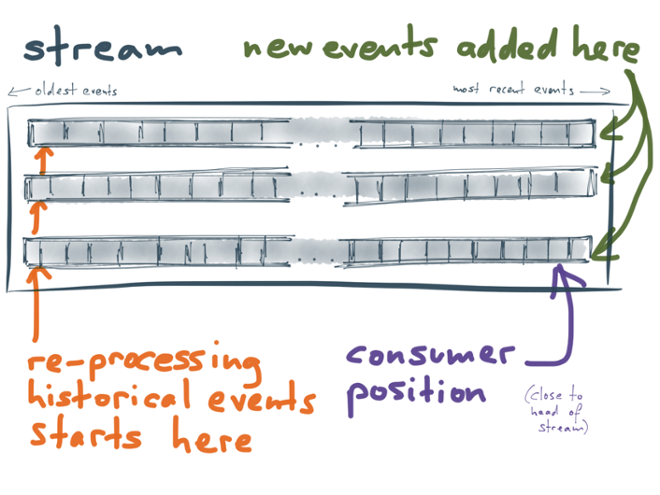
Now, whenever Luwak starts up, it can jump to the very beginning of the queries stream, and consume it from beginning to end. All queries in that stream are loaded into memory, so that Luwak knows what queries it should apply to documents. Only once it has finished consuming the stream, Luwaks starts processing documents and matching them against queries. We call the query stream a bootstrap stream, because it’s used to bootstrap (initialize) the in-memory state of the stream consumer.
This brings us to Samza, a framework for writing stream processing jobs on top of Kafka. A basic Samza job is very simple: you write a bit of code (implementing a Java interface called StreamTask) and tell it which stream you want to consume, and Samza calls the process() method on your code for every message that is consumed from the input stream. The code can do whatever it wants, including sending messages to an output stream.
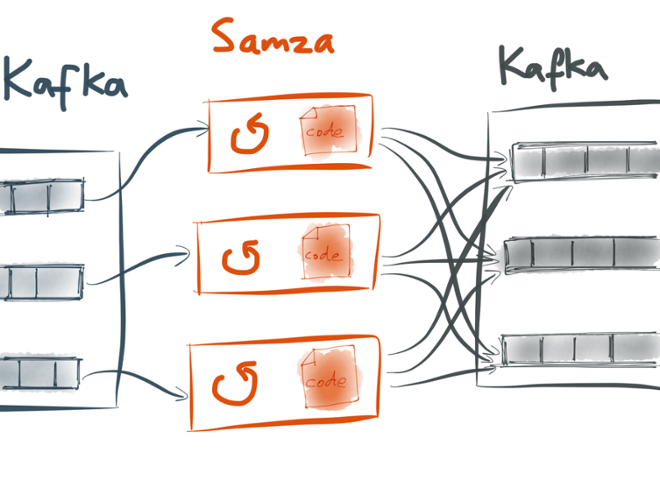
As the input stream from Kafka is split into partitions, Samza creates a separate StreamTask for each partition, and each StreamTask processes the messages in its corresponding partition sequentially. Although a StreamTask only processes input from one partition, it can send output to any partition of its output streams.
This partitioning model allows a Samza job to have two or more input streams, and “join” them together:
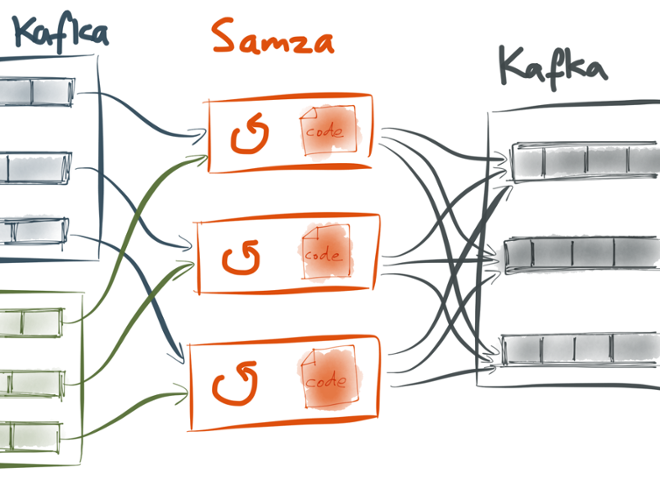
By default, if a job has two input streams (say A and B), Samza sends partition 1 of stream A and partition 1 of stream B to the same StreamTask 1; it sends partition 2 of A and partition 2 of B to the same StreamTask 2; and so on. This is illustrated in the picture above. Note this only really works if both input streams have the same number of partitions.
This allows the stream join to scale, by partitioning both input streams in the same way. For example, if both streams are partitioned by user ID (i.e. using the user ID as the Kafka message key), then you can be sure that all the messages for a particular user ID on both input streams are routed to the same StreamTask. That StreamTask can then keep whatever state it needs in order to join the streams together.
How do we bring full-text search on streams into this processing model?
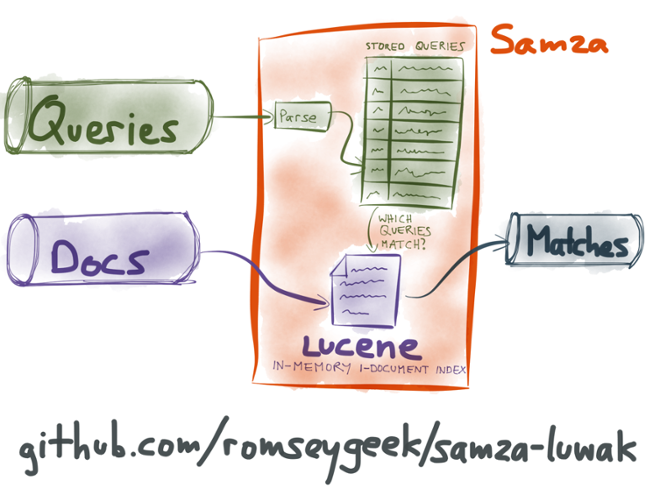
Alan and I hacked together a proof-of-concept called Samza-Luwak to test using Luwak inside a Samza job. It works as follows:
There are two input streams (Kafka topics): one for queries, and one for documents. The query stream is a bootstrap stream with compaction, as described above. Whenever a user wants to register, modify or unregister a query, they send a message to the queries stream. The Samza job consumes this stream, and whenever a message appears, it updates Luwak’s in-memory roster of queries.
The documents stream contains the things that should be matched by the queries (the tweets if you’re building Twitter search, the web pages from the crawler if you’re building Google Alerts, etc). The Samza job also consumes the documents stream, and whenever a document appears, it is matched against the index of registered queries, as described previously. It then sends a message to an output stream, indicating which queries matched.
How do we distribute this matching process across multiple machines? The problem is that Samza’s default partitioning model actually doesn’t do what we need. As I said previously, Samza by default sends partition 1 of all the input streams to task 1, partition 2 of all the input streams to task 2, and so on:
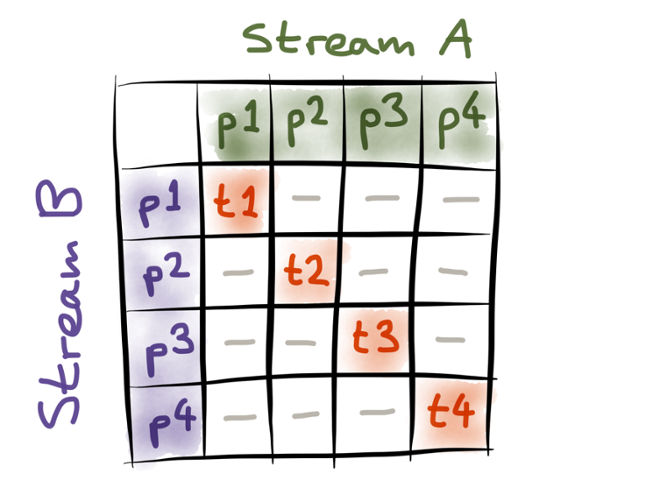
This is a good partitioning model if you’re doing an equi-join, because you can set up the partitioning of the input streams such that each tasks only needs to know about its own input partitions, and can ignore all the other partitions. This allows you to increase parallel processing and scale the computation simply by creating more partitions.
However, full-text search is different. We’re not doing an equi-join on a particular field, we’re trying to find matches involving arbitrarily complicated boolean expressions. In general, we don’t know in advance which documents are going to match which queries. (The query index tells us *approximately* which queries might match, but it’s not precise enough to use for partitioning.)
We still want to partition the query and document streams, because that will allow the system to scale. But we also want to be able to match every document against every possible query. In other words, we need to make sure that every query partition is joined with every document partition:
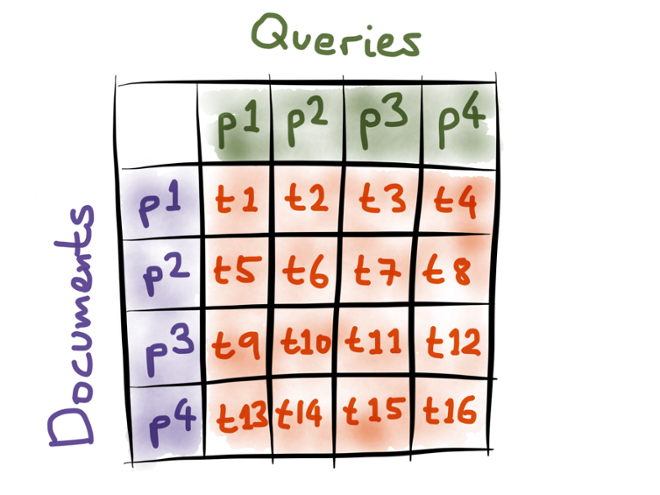
If you think about it, what we need is a cartesian product of query partitions and document partitions. We want to create a separate StreamTask for every possible combination of a query partition and a document partition. For example, in the picture above, StreamTask 8 is responsible for handling query partition 4 and document partition 2.
This gives us exactly the semantics we need: every query is sent to multiple tasks (one task per document partition), and conversely, every document is sent to multiple tasks (one task per query partition). Each task can independently do its work on its own partitions, and afterwards you just need to combine all the matches for each document. The dataflow is similar to the scatter-gather approach you get in distributed search engines.
Unfortunately, this mode of streaming joins is not yet supported in Samza, but it’s being worked on (you can track it under if you’re interested). Once this feature is in place, you’ll be able to perform full-text search on streams at arbitrary scale, simply by adding new partitions and adding more machines to the cluster. Combining the clever indexing of Luwak with the scalability of Kafka and Samza — isn’t that cool?
If you want to play with Samza, there’s a quickstart project “hello-samza”, and you can find our
proof-of-concept integration of Samza and Luwak on Github.
Alan Woodward is a director of Flax. He is a committer on Lucene/Solr and developer of Luwak. He previously worked on the enterprise search product Fast ESP.
Martin Kleppmann is a committer on Apache Samza and author of the upcoming O’Reilly book Designing Data-Intensive Applications. He previously co-founded Rapportive, which was acquired by LinkedIn.










